How Big Data Is Changing Medicine


How Big Data Is Changing Medicine
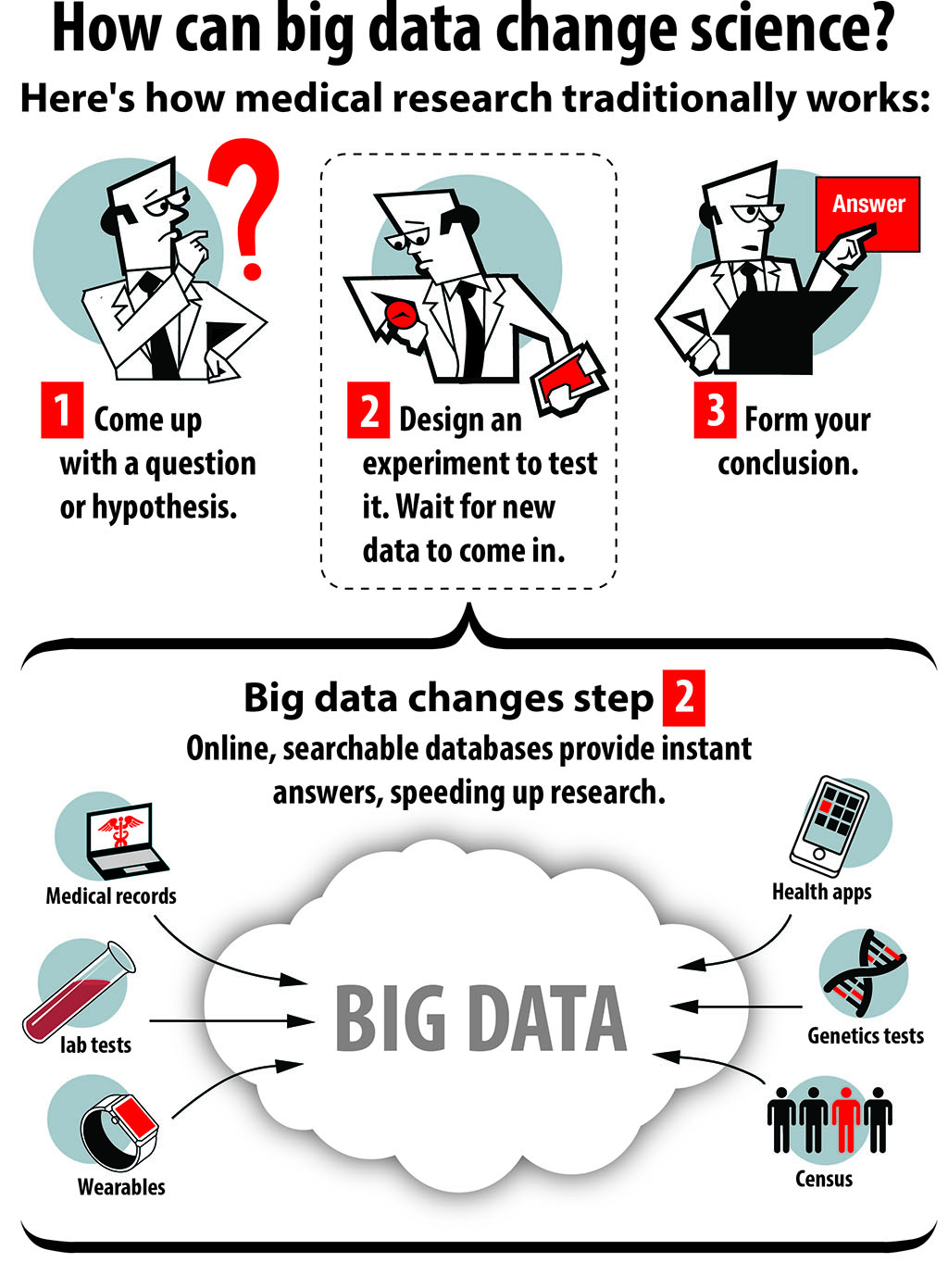
Here’s how science usually works: Come up with a question or a hypothesis. Develop an experiment to test it and create data. As any middle school student could tell you, it’s called the scientific method.
Now, some researchers and entrepreneurs in the Bay Area say that method is being upended, especially when it comes to medicine.
Consider what happened in the pediatric intensive care unit at Stanford’s Lucile Packard Children’s Hospital a few years ago.
In 2011, a young girl from Reno, Nevada, was flown by helicopter to the pediatric intensive care unit of the hospital.
“She was gravely ill. Her kidneys were shutting down,” recalls Jennifer Frankovich, at the time a young attending physician at the hospital.
The girl had been given morphine to dull her crushing abdominal pain. To Frankovich, the girl’s parents, who were from Mexico, looked like deer in the headlights.
“There were probably more doctors around her bed than they’d seen in their lives" she says. "I mean, the kidney doctor, the intensivist, the rheumatology team, the hematology team. There was a huge number of doctors around this poor girl’s bed.”
Weighing the Risks
Tests showed the girl had lupus, a disease in which the immune system goes rogue, attacking the body’s healthy tissues. Lupus can cause permanent kidney damage.
But Frankovich worried about something else, too. She’d seen kids like this before, and recalled that some of them also developed blood clots, which can travel to the heart or lungs and be deadly.
Blood clots can be prevented with an anti-coagulant, which keeps the blood flowing. But that, too, carries risks. A patient on blood thinners can have a stroke or bleed into an organ. Blood thinners can also complicate surgery.
Giving the drug was risky. Not giving the drug was also risky. Frankovich asked her colleagues: What should we do here?
“There wasn’t enough published literature to guide this decision,” Frankovich says. “[They said] the best route was to not do anything.”
Pediatric lupus is rare, which makes formal studies hard to come by. It would take years for a single institution to identify enough subjects to come up with a meaningful sample size.
And the question itself was fairly obscure. Whether or not pediatric lupus patients are at a high risk for developing blood clots is one of those matters that medical researchers haven’t gotten around to answering.
Frankovich needed data. And that is when she had her big idea.
An Unconventional Decision
Frankovich had been helping build a database of pediatric lupus patients who had been seen previously at the hospital. She had digitized the charts and made them searchable with key words.
This isn’t typical.
Like any chronic medical condition, lupus generates a staggering amount of paperwork. Doctors follow each patient for years, even a decade.
“Our pediatric lupus patients have enough records to fill boxes,” Frankovich says.
She says the accumulated records of every kid with lupus who has come through Packard Hospital would fill a large room.
But now, all that data was accessible with a keystroke.
By looking for patterns within those medical records, Frankovich realized, she would, in a sense, be doing the study no one else had gotten around to doing.
She could look at every pediatric lupus patient that had come through the hospital to see how many of them developed blood clots, and what the risk factors were.
Based on that, she could calculate whether the risks of a blood clot in her current patient justified the risks of prescribing an anti-coagulant.
So she ran the search and presented her findings to her colleagues.
“And universally everyone said, ‘wow, based on those numbers, it seems like we should try to prevent a clot in her,’” Frankovich says.
The patient was given the anti-coagulant. Over time her lupus got better. As far as Frankovich knows, she’s doing well.
It may not seem like it, but what Frankovich did was fairly radical, noteworthy enough to warrant a paper published in November 2011 in the New England Journal of Medicine.
Traditionally, doctors make decisions based on two factors: One, their own expertise and that of other doctors and specialists. In other words, that team of doctors who were gathered around the young lupus patient’s bed.
Two, doctors consult the scientific literature. They read studies and case reports that have been published in established medical journals.
Frankovich was taking a third route. She was using electronic medical records to search for answers that were already out there, but hadn’t been uncovered yet.
A Seismic Shift in Medicine
It’s an example, says Atul Butte, an entrepreneur and associate professor of pediatrics at the Stanford School of Medicine, of a seismic shift happening in medicine.
“The idea here is, the scientific method itself is growing obsolete,” Butte says.

This concept draws from an essay published in Wired Magazine in 2008 called “The End of Theory.”
According to the essay, so much information will be available at our fingertips in the future that there will be almost no need for experiments. The answers are already out there.
“Think about it,” Butte says. “The scientific method -- we learned this in elementary school -- is: We come up with a question, a hypothesis, and go make measurements to answer it. Now we’re living in this world where we already have the measurements and the data. The struggle is to figure out: What do we want to ask of all that data?”
Take, for example, a question Butte’s team has focused on recently: the rise in pre-term births in the United States. One theory, says Butte, points to an increase in exposure to environmental toxins.
Traditionally, this would be a challenging hypothesis to study. Medical records for these births aren’t necessarily in any one place, online. The same problem exists with records on air pollution, or weather patterns.
But that’s changing.
Now, Butte says, “you can connect pre-term births from the medical records and birth census data to weather patterns, pollution monitors and EPA data to see is there a correlation there or not.”
Correlation does not mean causation (as any statistician will tell you) but it’s a good jumping-off point for more targeted research.
The Ever-Expanding Cloud of Information
Big data is more than medical records and environmental data, Butte says. It could (or already does) include the results of every clinical trial that’s ever been done, every lab test, Google search, tweet. The data from your Fitbit.
Eventually, the challenge won’t be finding the data, it’ll be figuring out how to organize it all.
“I think the computational side of this is, let’s try to connect everything to everything,” Butte says.
Perhaps the biggest pool of data will be the genetic instructions written in each one of our cells.
It took $2.7 billion and 13 years to sequence the first human genome. Today, that same project costs $1,500 and takes about a day.
“We’re heading to a world where we’re going to have the genome sequence of everyone on planet Earth,” Butte says.

One of the world’s largest genetics databases belongs to the Mountain View-based company 23andMe.
CEO Anne Wojcicki says that huge pool of data is already providing answers.
Take for example, she says, a family that came to the company to learn more about three family members who had developed pancreatic cancer.
The family members also shared a specific gene mutation. They wanted to know: Is the mutation causing the cancer?
23andMe consulted its database of more than 500,000 partial genetic profiles. They found 157 people with the same mutation.
“What we saw,” Wojcicki says, “is that of those 157 people with that mutation, the majority said they don’t have the cancer, nor does anyone in their immediate family."
"So we were very quickly able to conclude, not with 100 percent certainty," she says, "but with a high degree of certainty, that the mutation the family thought was causing pancreatic cancer was not causing the cancer.”
Normally, she says, this kind of question would require expensive research grants. Researchers would have to recruit subjects with and without the disease and then run genetic tests on all of them.
23andMe’s searchable database meant the answers were already there.
“We’re able to take the timeline down from years of research to a couple weeks,” Wojcicki says.
For 23andMe, big data is a business model. The company anonymizes its genetics information and sells it to researchers who want to study the genetic basis for Parkinson’s disease or diabetes, for example.
It recently teamed up with Pfizer on a project to research inflammatory bowel syndrome. In July, the company announced a $1.37 million grant from the National Institutes of Health to develop its database and research engine.
This work raises questions about privacy, and about who gets access to this data.
What’s Safer? Data Or a Team of Doctors?
And when medicine meets big data there are always questions about safety.
Remember Dr. Frankovich and the lupus patient?
Given the success of that experiment, you might think what she did is now standard at the hospital where she works. In fact, it’s the opposite.
“We’re actually not doing that anymore, says Frankovich.
In the end, hospital administrators decided -- at least in urgent cases where time is short -- that it is still safer to trust the wisdom of a team of doctors than to search medical records for data about what’s worked in the past.
Frankovich agrees. Analyzing data is complicated and requires specific expertise. What if the search engine has bugs, or the records are transcribed incorrectly? There’s just too much room for error, she says.
“It’s going to take a system to interpret the data,” she says. “And that’s what we don’t have yet. We don’t have that system. We will, I mean for sure, the data is there, right? Now we have to develop the system to use it in a thoughtful, safe way.”